Spring 循环依赖问题
首先上总结
针对 Spring Bean 的循环依赖问题,如果情况允许,尽量不使用临时规避的手段容忍循环依赖问题。如果因存量代码的问题,尽量将消除循环依赖作为高优先级历史债务进行解决。
在 Spring Boot 2.6.0 版本开始,默认禁用对循环依赖的支持。也就是说,Spring Boot 2.6.0 版本及之后版本,如果存在循环依赖,不管是何种场景,都会报启动错误。如果期望启用对循环依赖的支持,则可以先在配置文件中补充下述配置,做临时规避处理。即配置 spring.main.allow-circular-references=true。
对于 Bean 多例(Prototype)场景,Spring 是不支持解决该场景的循环依赖,只支持 Bean 单例(Singleton)的场景(不支持都是构造器注入的场景)。 ,从而解决了循环依赖重复创建的问题。这里以 A 属性注入 B,B 属性注入 A 为例,介绍 Spring 是如何支持循环依赖的。首先在创建 A 的实例时,会先创建 A 的对象引用,然后再去查找 A 依赖的对象,如果不存在,则需要进入依赖对象的创建过程,同样地,会先创建对象的引用,这里是对象B的引用。这样在 A 中就可以使用 B,而 B 也是类似的操作。
什么是循环依赖
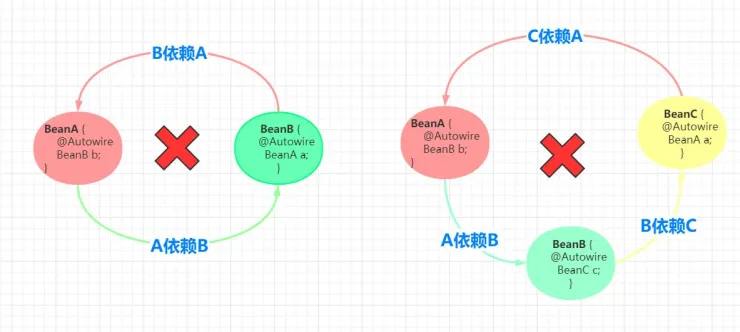
类与类之间的依赖关系形成了闭环,就会导致循环依赖问题的产生。举例来说,假设存在两个服务类 A 和服务类 B,如果 A 通过依赖注入的方式引用了 B,且 B 通过依赖注入的方式引用了 A,那么 A 和 B 之间就存在循环依赖。
推广来说,如果涉及多个类,也存在这种依赖关系,那么也是循环依赖问题。
循环依赖问题比较严重,有时会影响服务启动,有时会导致死循环调用(如果线上环境出现循环调用,会导致程序进入死循环,然后服务崩溃,进而导致用户请求无法响应,造成生产事故),应引起足够的重视。
举个例子:
@Component
public class Bean1 {
@Autowired
Bean2 bean2;
}@Component
public class Bean2 {
@Autowired
Bean1 bean1;
}2.6 版本以上的 spring 启动时会报错:
Error starting ApplicationContext. To display the condition evaluation report re-run your application with 'debug' enabled.
2024-06-12T13:52:10.745+08:00 ERROR 4682 --- [demo] [ main] o.s.b.d.LoggingFailureAnalysisReporter :
***************************
APPLICATION FAILED TO START
***************************
Description:
The dependencies of some of the beans in the application context form a cycle:
┌─────┐
| bean1 (field cn.clear.demo.bean.Bean2 cn.clear.demo.bean.Bean1.bean2)
↑ ↓
| bean2 (field cn.clear.demo.bean.Bean1 cn.clear.demo.bean.Bean2.bean1)
└─────┘
Action:
Relying upon circular references is discouraged and they are prohibited by default. Update your application to remove the dependency cycle between beans. As a last resort, it may be possible to break the cycle automatically by setting spring.main.allow-circular-references to true.
Process finished with exit code 1Spring 如何检测循环依赖
Spring 检测循环依赖的方式也比较简单,在创建 bean 的时候可以给一个标签,表明当前 bean 正在创建,然后递归的创建依赖的 bean,递归创建的过程中如果发现依赖的 bean 已经处于创建中的状态,就说明存在循环依赖了,存在循环依赖并不会直接报错,只有 Spring 无法自动解决的时候才会报错。
处理循环依赖
Spring 能处理哪些循环依赖的情况?
先说结论:如果存在一个依赖闭环,我们称这个闭环中最先被 Spring 创建的 Bean 为闭环中的第一个 Bean(Spring 按照字典序创建 Bean),如果这个 Bean 是构造器注入,其它 Bean 不管是构造器注入还是 Set 方法注入,Spring 都无法自动解决,并且会在启动的时候报错提醒。简单来说就是只要存在依赖闭环,并且闭环中第一个 Bean 是构造器注入,其它 bean 不管是构造器注入还是 Set 方法注入,这些情况 Spring 都无法自动解决,其余情况 Spring 都能自动解决。
在分析原因之前先来说说 Spring 处理循环依赖的主要理论依据,我们知道 Spring Bean 说到底也是 java 对象,bean 之间的依赖关系说到底也就是对象之间的引用关系,比如 BeanA 依赖 BeanB,实际上就是 A 对象中的一个属性保持了对 B 对象的引用,从这个角度来说 Spring 创建 bean 并处理依赖关系的过程可以简单的认为就是实例化一个 java 对象并填充 java 对象属性的过程。那 java 对象的属性可以在什么时候填充呢?最为常见的有两种,第一种是使用有参构造器,在实例化的时候就填充上;第二种是先通过无参构造器把对象实例化出来,然后通过属性的 set 方法填充,在 Spring 中这两种方式分别对应构造器注入和 Set 方法注入。Set 方法注入相比构造器注入的不同就在于使用 Set 方法进行注入的时候 bean 已经实例化出来了,只是属性暂时还没填充完整,这种 bean 被称为提前暴露的 bean。bean 之间建立依赖关系只要有一个对象的引用就可以了,至于这个对象的属性是否已经填充完整并不关心,这些属性可以延后填充, 所以提前暴露出来的 bean 虽然不完整但已经可以注入到其它 bean 了。
这就是 Spring 自动解决循环依赖的理论依据:当出现循环依赖的时候可以先把依赖闭环中第一个 bean 实例化并提前暴露出来,这样闭环上依赖这个 bean 的 bean 就可以创建完成,这个 bean 创建出来之后,依赖这个 bean 的下一个 bean 也就可以创建出来,从而整个递归能够顺利进行下去,当跳出最后一层递归之后第一个 bean 依赖的 bean 也已经创建出来了,只要将这个 bean 再注入到第一个 bean 中整个闭环上所有 bean 就都创建完成了。文字描述比较抽象,举个例子,假如 A 依赖 B,B 依赖 C,C 又依赖 A,先把 A 实例化并暴露出来,这个样 A 的引用已经有了并且能被其它 bean 发现。由于 A 依赖 B,所以接下来尝试去创建 B,发现 B 又依赖 C,所以尝试去创建 C,发现 C 又依赖 A,这个时候发现 A 的引用已经有了,所以直接注入到 C,C 能顺利创建,C 创建完成之后 B 也就能顺利创建,B 创建完之后,将 B 注入 A,A 也就创建完成了,整个依赖闭环上的 Bean 都创建成功了。关键就在于依赖闭环的第一个 Bean 能不能提前暴露出来,为什么一定是第一个呢?因为最后一个 Bean 总会依赖第一个 Bean,如果第一个 Bean不能提前暴露出来,最后一个 Bean 就无法创建完成,从而导致整个递归过程失败。哪种情况第一个 Bean 无法提前暴露出来呢?没错,就是第一个 Bean 使用构造器注入的时候。
Spring 的三级缓存
我们称 Spring 为容器,容器从字面意义上就是存放东西的器皿,那 Spring 作为容器存放了什么呢?没错,就是 Bean,最终所有的单例 Bean 都会存放到 Spring 的单例池中。但是在 Spring 启动的时候单例 Bean 并不是一开始就存放到了单例池的,而是使用了三级缓存,创建的过程中会按照需要放入到不同的缓存,但最终都会移入到单例池中,单例池实际上就是三级缓存中的第一级缓存,看 DefaultSingletonBeanRegistry 类的源码:
/** Cache of singleton objects: bean name to bean instance. */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/** Cache of singleton factories: bean name to ObjectFactory. */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
/** Cache of early singleton objects: bean name to bean instance. */
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16); 所谓三级缓存就是三个 Map,Spring 官方并没有直接指明层级,不过根据代码,singletonObjects 总是最先被查询,我们姑且称为一级缓存,以此类推,earlySingletonObjects 为二级缓存,singletonFactories 为三级缓存。它们各自的含义如下:
singletonObjects:singletonObjects即一级缓存,也是最终存放所有单例 bean 的单例池,所以这个缓存中存放的是完整的单例 bean,什么是完整的单例 bean 呢?就是经历了 bean 生命周期完整的创建过程,能够交付使用的 bean。所有创建完成的单例 bean 最终都会放入到这个缓存中,而二级缓存earlySingletonObjects和三级缓存singletonFactories都只是临时的缓存,容器创建 bean 的过程中会用到,但是最终这两个缓存中的 bean 都会移入一级缓存也就是单例池中,所以最终这两个缓存都是空的。earlySingletonObjects:earlySingletonObjects即二级缓存,这个缓存用来存放实例化完成但是还没将属性装配完成的单例 bean,也就是前面提到的那些提前暴露的 bean,只有出现循环依赖的时候才需要把 bean 提前暴露出来,所以也只有出现循环依赖的时候才会用到二级缓存。singletonFactories:singletonFactories即三级缓存,这个缓存如果翻译成中文是“bean 工厂缓存”,听名字很容易与BeanFactory混淆,BeanFactory是 Spring 容器的顶层接口,BeanFactory就是 Spring 容器,但是这里的“bean 工厂缓存”与容器BeanFactory没有任何关系,三级缓存这个Map的 value 是ObjectFactory接口类型,ObjectFactory中只有getObject()一个接口方法,与 Spring 容器的顶层接口BeanFactory是两个不同的类,所以没有任何关系。我们从三级缓存中取出缓存的ObjectFactory之后,需要调用getObject()方法来获取 bean 对象,所以这个ObjectFactory相当于一个临时的容器,这个容器中只装了一个 bean,所以三级缓存实际存的是当前 bean 的一个临时容器,如果要从三级缓存中取出 bean,就要先取出这个临时容器,然后从临时容器中把 bean 取出来,这和前两级缓存是不太一样的,一、二级缓存的Map的 value 直接存的就是 bean 对象,取出来就是 bean 对象,后面会讲解 Spring 为什么要这么设计。三级缓存singletonFactories也是一个临时的缓存,任何一个单例 bean 实例化完成之后都会先包装为一个ObjectFactory对象,然后放入到这个缓存。
三级缓存的使用过程
在没有 AOP 的情况下我们来看三级缓存的实际使用过程,这里描述四种情况下缓存的使用涵盖了所有的场景:
BeanA和BeanB没有依赖关系BeanA依赖BeanB,BeanB不依赖BeanABeanA不依赖BeanB,BeanB依赖BeanABeanA和BeanB互相依赖,也就是循环依赖
在往下阅读之前先声明一下,Spring 创建一个 bean 可以简化的看成两个步骤,第一步是实例化 bean;第二步是填充属性,也就是处理依赖关系,本文中将第二步填充属性称之为“装配 bean”,所以后文出现“装配 bean”的描述,含义就是处理 bean 的依赖关系。同时当读者在下文中看到“创建 bean”字样的时候,要理解这个“创建”实际是包含了两个步骤的,两步都完成才算创建完成。
在下文中还会出现“移入”的字样,比如“把 bean 从三级缓存中移入到一级缓存”这样的描述,这里的“移入”指的是 DefaultSingletonBeanRegistry 类中 addSingleton 方法的逻辑:
// DefaultSingletonBeanRegistry类中的addSingleton方法
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
this.singletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}这段代码实际上是把 bean 放入到一级缓存,同时从二级缓存和三级缓存中移除,整体来看相当于将 bean 从二级缓存或三级缓存移入到一级缓存,所以使用“移入”这样一个词来描述这个过程。
声明结束之后来看四种情况下三级缓存的具体使用情况:
BeanA和BeanB没有依赖关系
Spring 按照字典序创建 bean,所以 Spring 先创建 BeanA。创建的第一步先实例化 BeanA,实例化完成之后把 BeanA 包装为 ObjectFactory 对象放入到三级缓存 singletonFactories 中,然后进行 BeanA 的装配,装配过程发现 BeanA 没有依赖,装配结束;然后把 BeanA 从三级缓存 singletonFactories 直接移入到一级缓存,也就是单例池中, BeanA 创建完成。然后开始创建 BeanB,BeanB 是同样的过程,所以不再赘述。
这个过程中缓存使用是:三级缓存 singletonFactories >> 一级缓存 singletonObjects
BeanA依赖BeanB,BeanB不依赖BeanA
Spring 同样首先创建 BeanA,第一步先实例化 BeanA,实例化完成之后把 BeanA 包装为 ObjectFactory 对象放入到三级缓存 singletonFactories 中,然后进行 BeanA 的装配,发现 BeanA 依赖 BeanB,Spring 会去容器中查找 BeanB,也就是从这三个缓存中查找,会发现三个缓存中都没有 BeanB,Spring 就知道 BeanB 还没创建,所以先去创建 BeanB,同样先实例化 BeanB,实例化完成之后把 BeanB 包装为 ObjectFactory 对象放入到三级缓存 singletonFactories 中,然后进行 BeanB 的装配,发现 BeanB 没有依赖,BeanB 装配结束,把 BeanB 从三级缓存直接移入到一级缓存,BeanB 创建完成;回过头来继续装配 BeanA,在 BeanA 中注入 BeanB,完成之后 BeanA 装配结束;然后把 BeanA 从三级缓存移入到一级缓存,BeanA 创建结束。
这个过程中缓存使用是:三级缓存 singletonFactories >> 一级缓存 singletonObjects
BeanA不依赖BeanB,BeanB依赖BeanA
Spring 首先创建 BeanA,第一步先实例化 BeanA,实例化完成之后把 BeanA 包装为 ObjectFactory 对象放入到三级缓存 singletonFactories 中;然后进行 BeanA 的装配,发现 BeanA 没有依赖,装配结束,再把 BeanA 从三级缓存直接移入到一级缓存,BeanA 创建结束。然后创建 BeanB,同样先实例化 BeanB,实例化结束之后将 BeanB 包装为 ObjectFactory 对象放入到三级缓存 singletonFactories 中;然后进行 BeanB 的装配,发现 BeanB 依赖 BeanA,spring 就去容器中查找 BeanA,并在一级缓存中找到,将 BeanA 注入到 BeanB 中,装配结束;然后将 BeanB 从三级缓存移入到一级缓存,BeanB 创建结束。
这个过程中缓存使用是:三级缓存 singletonFactories >> 一级缓存 singletonObjects
BeanA和BeanB互相依赖
Spring 首先创建 BeanA,第一步先实例化 BeanA,实例化完成之后把 BeanA 包装为 ObjectFactory 对象放入到三级缓存 singletonFactories 中;然后进行 BeanA 的装配,发现 BeanA 依赖 BeanB,Spring 会去容器中查找 BeanB,发现 BeanB 还没有创建,所以先去创建 BeanB,同样先实例化 BeanB,实例化结束之后将 BeanB 包装为 ObjectFactory 对象放入到三级缓存中;然后进行 BeanB 的装配,发现 BeanB 依赖 BeanA,Spring 会去容器中查找 BeanA,也就是从三个缓存中查找,会发现 BeanA 在第三级缓存中,第三级缓存存放的是 ObjectFactory 对象,取出 ObjectFactory 对象之后调用 getObject() 方法获取到 BeanA,拿到 BeanA 之后会放入到二级缓存 earlySingletonObjects 中,顺便在三级缓存中把 ObjectFactory 对象移除,这个过程相当于将 BeanA 从第三级缓存移入到了第二级缓存,尽管 BeanA 还没装配结束,但总之是获取到了 BeanA,将获取到的 BeanA 注入到 BeanB,BeanB 装配结束;装配结束之后将 BeanB 从三级缓存移入到一级缓存,BeanB 创建完成;然后回过头来继续装配 BeanA,将 BeanB 注入 BeanA,BeanA 装配结束;将 BeanA 从二级缓存移入到一级缓存,BeanA 创建结束。
这个过程中
BeanA的缓存使用:三级缓存singletonFactories>> 二级缓存earlySingletonObjects>> 一级缓存singletonObjectsBeanB的缓存使用:三级缓存singletonFactories>> 一级缓存singletonObjects
以上过程都是通过调试代码得出的,我们知道 Spring 容器的启动是从 refresh() 方法开始的,在 refresh() 方法中会调用 finishBeanFactoryInitialization() 方法,该方法会创建出所有非懒加载的 bean,将这个方法作为入口进行调试,如果感兴趣可以用同样的方式进行调试。
三级缓存使用过程中重要的三个方法
整个调用过程还是很复杂的,但是其中最重要的就只有三个方法,这三个方法中主要步骤我都进行了注释,由于三个方法都比较长,所以后面在贴源码的时候省略掉了中间那些对理解无关紧要的代码,比如异常处理等,如果想看完整的代码,建议直接看源码。一定要跟着源码调试一遍,调试是学习源码最好的方法。
DefaultSingletonBeanRegistry#getSingleton
bean 的入口,这个方法最终会调用到 AbstractAutowireCapableBeanFactory 类的 doCreateBean() 方法来真正创建和装配 bean,也就是第二个重要的方法。注意 DefaultSingletonBeanRegistry 类还有一个重载的 getSingleton() 方法,这是第三个重要的方法(后面有展示),这两个方法的参数不同,功能也不一样,后一个 getSingleton() 方法用来从缓存中查找 bean。
/**
* DefaultSingletonBeanRegistry类的getSingleton方法,这个方法是创建bean的入口,后面还有一个getSingleton方法,两个方法的参数不同,功能也不一样,后一个getSingleton方法用来从缓存中查找bean
*/
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
// 1、此处getObject方法最终会调用到AbstractAutowireCapableBeanFactory类的doCreateBean方法,也就是真正去创建一个bean的地方,也就是第二个重要的方法
singletonObject = singletonFactory.getObject();
newSingleton = true;
if (newSingleton) {
// 2、当bean创建完成之后将bean从三级缓存或二级缓存移入到一级缓存,整个创建过程就结束了
addSingleton(beanName, singletonObject);
}
}
return singletonObject;
}AbstractAutowireCapableBeanFactory#doCreateBean
这个方法用来真正实例化 bean、处理依赖关系、增强 bean 的功能。处理依赖关系的时候会去查找它依赖的 bean,所以最终又会调用到 DefaultSingletonBeanRegistry 类中用于查找 bean 的 getSingleton() 方法,也就是第三个重要的方法。
/**
* AbstractAutowireCapableBeanFactory类的doCreateBean方法,这个方法用来真正实例化和装配bean
*/
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
BeanWrapper instanceWrapper = null;
...
if (instanceWrapper == null) {
// 1、实例化一个bean
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
Object bean = instanceWrapper.getWrappedInstance();
...
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
// 2、将实例化的bean包装为ObjectFactory对象,放入到三级缓存singletonFactories中
// 注意第二个参数是一个lambda表达式,实际上是ObjectFactory函数式接口,这个接口只有getObject()一个方法,用来返回bean,如果没有AOP,返回的就是上面实例化的bean对象,但如果有AOP,返回的将是代理对象
// 由于是一个lambda表达式,所以getEarlyBeanReference()方法并不会立刻执行
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
Object exposedObject = bean;
// 3、populateBean方法用来装配bean,也就是依赖注入,当发现依赖关系之后会去容器中查找依赖的bean,查找的过程最终会调用到DefaultSingletonBeanRegistry类中重载的的getSingleton方法,也就是第三个重要的方法
populateBean(beanName, mbd, instanceWrapper);
// 4、bean功能的增强(aware接口、bean后置处理器、初始化方法),AOP的代理对象在这里生成
exposedObject = initializeBean(beanName, exposedObject, mbd);
if (earlySingletonExposure) {
// 从缓存中获取对象,注意第二参数是false,意味着只会从一级缓存和二级缓存获取,由于此时当前bean还没有创建完成,所以一级缓存必然没有当前bean,那么这次调用其实含义是从二级缓存中获取bean
// 所以如果此时bean还在三级缓存中,这里返回值earlySingletonReference将是null
// 但如果返回值不为null,说明bean从三级缓存移到了二级缓存,必然是循环依赖的场景,如果bean有AOP,这里earlySingletonReference将是代理后的bean;如果没有AOP,earlySingletonReference依然是原本的bean
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
}
...
}
}
... // 省略了部分代码
return exposedObject;
}DefaultSingletonBeanRegistry#getSingleton
这个方法用来从缓存中查找 bean
/**
* DefaultSingletonBeanRegistry类中重载的getSingleton方法,这个方法用来从缓存中查找bean
*/
// 注意第二个参数,如果第二个参数为false,意味着只会从前两级缓存中查找,不会去第三级缓存查找
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 从第一级缓存中查找
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
// 从第二级缓存中查找
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
synchronized (this.singletonObjects) {
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
// 从第三级缓存中查找,注意:从三级缓存中找到之后会移入到二级缓存
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}为什么一定要三个层级的缓存?
从上面使用三级缓存的过程中可以看到如果没有 AOP,二级缓存 earlySingletonObjects 只有在有循环依赖的情况下才会使用,但是不知道大家有没有一个疑问,为什么一定要有这个二级缓存 earlySingletonObjects 呢?比如 A 依赖 B,B 依赖 A 的循环依赖场景,假如 A 和 B 都是 set 方法注入并且 Spring 只有一级缓存和三级缓存,Spring 先实例化 A,A 实例化结束之后包装为 ObjectFactory 对象放入三级缓存,然后装配 A 的时候发现 A 依赖 B,就去尝试创建 B,先实例化 B,B 实例化结束之后包装为 ObjectFactory 对象放入到三级缓存中,然后装配 B,发现 B 依赖 A,A 已经在三级缓存中了,直接将 A 从三级缓存中获取到完成 B 的装配,B 创建完成,将 B 从三级缓存移入到一级缓存中;然后回过头来继续装配 A,从一级缓存中获取到 B 完成 A 的装配,A 创建完成,将 A 从三级缓存移入到一级缓存,A 和 B 都创建完成了,这样一分析是不是发现似乎只有一级缓存和三级缓存也可以解决循环依赖的问题?
确实,如果仅仅只是为了处理循环依赖的情况,两个层级的缓存已经完全足够,根本不需要三个层级的缓存,使用三个层级的缓存也不是为了提升效率之类想当然的理由。
其实前面的描述中已经提示了答案,我在前面描述的时候都加了一个前提条件:“如果没有AOP”,Spring 一定要使用三级缓存的目的其实是为了处理有 AOP 情况下的循环依赖问题。注意,如果仅仅只有 AOP 而没有循环依赖,也不会用到二级缓存,一定是有循环依赖才需要用到二级缓存。
我们知道 AOP 的底层原理是动态代理,通过代理来对功能进行增强,所以如果有 AOP 最终使用的必然是代理对象,比如我们对 A 进行了 AOP,那么最终注入到 B 的必然是 A 的代理对象。那么 A 的代理对象是什么时候生成的呢?如果没有循环依赖,AOP 的代理对象是在 Bean 后置处理器的后方法中生成的,Spring 执行 Bean 后置处理的后方法是在 initializeBean() 方法中,而 initializeBean() 方法是在 populateBean() 方法的后面,populateBean() 方法用来处理依赖关系,所以没有循环依赖的情况下 Spring 是先进行依赖注入,然后再生成代理对象。
if (instanceWrapper == null) {
// 1、实例化一个 bean
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
Object bean = instanceWrapper.getWrappedInstance();
...
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
// 2、将实例化的 bean 放入到三级缓存 singletonFactories 中,注意并不是直接把 bean 放入一个容器,第二个参数是一个 lambda 表达式,getEarlyBeanReference() 方法并不会立刻执行
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
try {
// 3、populateBean 方法用来装配 bean,也就是依赖注入
populateBean(beanName, mbd, instanceWrapper);
// 4、bean 功能的增强(aware 接口、bean 后置处理器的前后方法、初始化方法)
exposedObject = initializeBean(beanName, exposedObject, mbd);
} catch (Throwable ex) {
...
}但假如有循环依赖的情况,比如 A 和 B 循环依赖,且 A 有 AOP,A 先实例化出来,执行到注释 3 的位置,发现 A 依赖 B,就去尝试递归创建 B,B 先实例化,实例化之后执行到注释 3 的位置,发现 B 依赖 A,这个时候 B 需要的是 A 的代理对象,但是 A 的代理对象正常情况下要在在注释 4 的位置才生成,A 还没执行到注释 4 的位置呢,那怎么办呢,只能是 B 在注释 3 的位置也就是处理依赖关系的时候就提前把 A 的代理对象给生成出来,要怎么提前生成出来呢?B 是从三级缓存中获取 A,还记得第三级缓存是什么吗?对,是 ObjectFactory 接口,所以 B 从三级缓存中获取 A 是先获取到 ObjectFactory 对象,然后调用 ObjectFactory 对象的 getObject() 方法来获取 A,getObject() 方法的具体实现是 getEarlyBeanReference() 方法:
// 将实例化的 bean 包装为 ObjectFactory 对象放入三级缓存,这里是一个 lambda 表达式,表达式的内容就是 getObject 方法的具体实现
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));我们来看 getEarlyBeanReference() 方法的逻辑:
/**
* AbstractAutowireCapableBeanFactory中的getEarlyBeanReference方法
*/
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
// Spring 使用 AnnotationAwareAspectJAutoProxyCreator 这个 Bean 后置处理来处理 AOP,AnnotationAwareAspectJAutoProxyCreator 实现了 SmartInstantiationAwareBeanPostProcessor 接口,所以这里 if 条件就是判断当前 bean 是否需要进行 AOP 处理
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (SmartInstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().smartInstantiationAware) {
// 最终会调用到 AbstractAutoProxyCreator 类中的 getEarlyBeanReference 方法,生成代理对象
exposedObject = bp.getEarlyBeanReference(exposedObject, beanName);
}
}
return exposedObject;
}
/**
* AbstractAutoProxyCreator 类中的 getEarlyBeanReference 方法
*/
@Override
public Object getEarlyBeanReference(Object bean, String beanName) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
// 注意 earlyProxyReferences 存放的是原来的 bean,而不是代理过后的 bean
this.earlyProxyReferences.put(cacheKey, bean);
// 生成代理对象
return wrapIfNecessary(bean, beanName, cacheKey);
}可以看到在 getEarlyBeanReference() 方法中判断如果当前 bean 有 AOP,那么就会生成代理对象,否则就直接返回原对象。回到之前的场景,B 从三级缓存中先获取到 ObjectFactory 对象,然后调用 ObjectFactory 对象的 getObject() 方法,由于 A 有 AOP,所以 getObject() 方法返回的是代理对象,正常执行下去 B 会用代理对象完成依赖注入,然后 B 的创建过程完成,跳出递归后会继续执行 A 的流程,将 B 注入 A,完成依赖关系的装配,然后执行到注释 4 的位置,也就是 initializeBean() 方法,这个方法正常情况下会在 bean 后置处理器的后方法中生成代理对象,但是代理对象已经提前生成过了,如果再生成一个代理对象就不对了,所以这里不会再生成代理对象,而是返回原对象,看源码:
/**
* AbstractAutoProxyCreator 类中的 bean 后置处理器中的后方法
*/
@Override
public Object postProcessAfterInitialization(@Nullable Object bean, String beanName) {
if (bean != null) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
// 有 AOP 的情况下会调用 getEarlyBeanReference 方法,在 getEarlyBeanReference 方法中会将原本的 bean 放入到 earlyProxyReferences 中,所以 remove 出来的 bean 和参数中的 bean 是同一个,条件不成立,所以不会再生成一个新的代理对象
// 如果没有 AOP,就不会调用 getEarlyBeanReference 方法,earlyProxyReferences 是空的,remove 出来是 null,条件成立,就会生成一个代理对象
if (this.earlyProxyReferences.remove(cacheKey) != bean) {
return wrapIfNecessary(bean, beanName, cacheKey);
}
}
return bean;
}也就是说调用 initializeBean() 方法返回的仍然是原 bean,但是最终需要的又是代理过的对象,那怎么获取代理过的对象呢?还得从缓存中获取,此时一级缓存中还没有,三级缓存中存储的仍然是原本的 bean,如果总共只有两级缓存,是没办法获取到代理后的对象的,所以就需要一个另外的缓存来存储代理过后的对象,也就是二级缓存。实际上 B 从三级缓存中获取 ObjectFactory 对象,然后调用 getObject() 方法获取到 A 的代理对象之后,就将代理对象放入到了二级缓存,所以之后只需要从二级缓存中来获取到代理后的 bean 就可以了:
// 4、如果有AOP,initializeBean不会再生成代理对象,所以exposedObject仍然是原本的bean
exposedObject = initializeBean(beanName, exposedObject, mbd);
if (earlySingletonExposure) {
// 从缓存中获取bean,注意这里第二个参数是false,意味着只会从一级和二级缓存中获取bean,前面处理依赖关系的时候已经将代理对象放入到了二级缓存,所以这里实际上就是从二级缓存中把代理过后的对象给取出来
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
if (exposedObject == bean) {
// 将代理过后的对象赋给exposedObject
exposedObject = earlySingletonReference;
}
...
}
}
...
return exposedObject;最后将这个返回 exposedObject 对象放入到一级缓存(单例池)中,BeanA 就创建结束了。
总结一下,在有循环依赖并且第一个 bean 有 AOP 的情况下,需要将第一个 bean 提前暴露出来,并且提前暴露出来的还要是代理过后的 bean,这个暴露出来的 bean 必须有一个地方存储,由于第三级缓存中存放的是原始的 bean,而且 bean 没有装配完成的情况下也不能放入到一级缓存中,所以必须要要有二级缓存来存放提前暴露出来的代理过后的 bean,这才是必须使用三个缓存的原因。
所以 Spring 使用三级缓存不是为了什么提升效率之类想当然的理由,而是有明确目的的。但其实看了源码就知道完成同样的功能用两级缓存也不是绝对不可以,不过那就是另一套实现方式了,任何时候实现相同的功能都可以有不同的方式,没有什么是绝对的,最终经受考验的是哪种方式效率更高、更容易让人理解。