ClickHouse 基本使用
首先,放一个官方文档的连接:点此进入
什么是 ClickHouse
ClickHouse 是一个高性能、面向列的 SQL 数据库管理系统(DBMS),用于在线分析处理(OLAP)
什么是 OLAP?
OLAP 场景要求在大型数据集之上对具有以下特征的复杂分析查询进行实时响应:
数据集可以是巨大的-数十亿或数万亿行
数据被组织在包含许多列的表格中
只选择几列来回答任何特定的查询
结果必须在毫秒或秒内返回
面向列的数据库与面向行的数据库
在面向行的 DBMS 中,数据存储在行中,与行相关的所有值都存储在一起。
在面向列的 DBMS 中,数据存储在列中,来自相同列的值存储在一起。
为什么面向列的数据库在 OLAP 场景中效果更好
面向列的数据库更适合 OLAP 场景:它们在处理大多数查询时至少快 100 倍。原因在下面进行了详细解释,但事实更容易在视觉上展示:
面向行的 DBMS
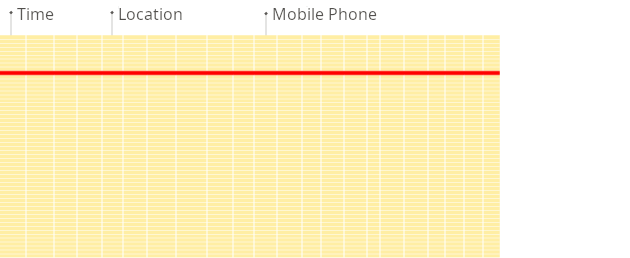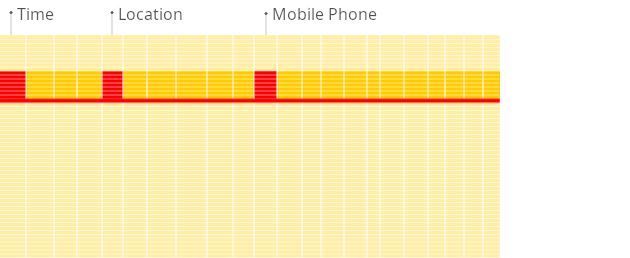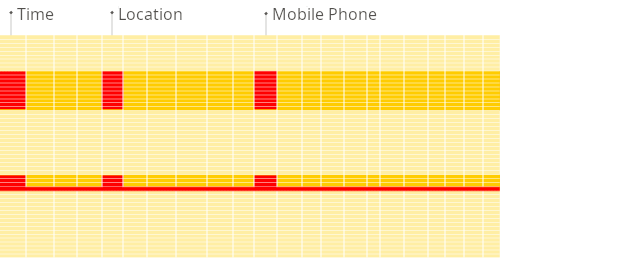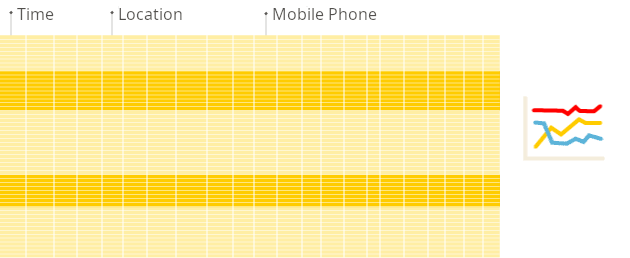
面向列的 DBMS
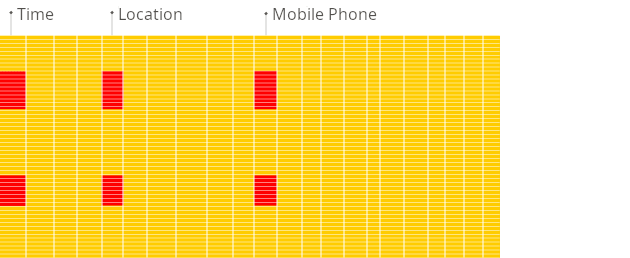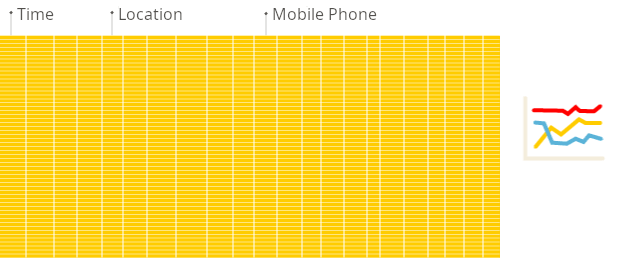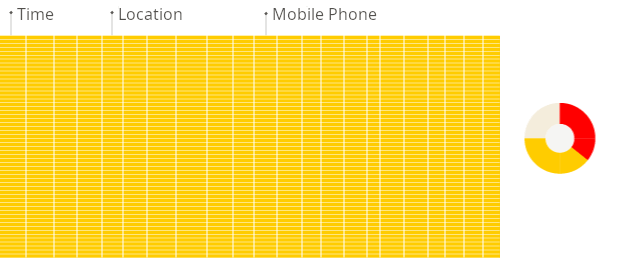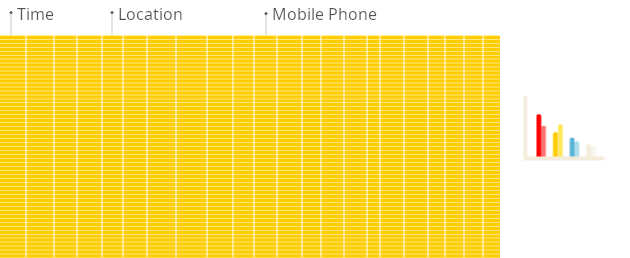
数据类型
整数类型:有符号和无符号整数(
UInt8,UInt16,UInt32,UInt64,UInt128,UInt256,Int8,Int16,Int32,Int64,Int128,Int256)浮点数:浮点数(
Float32和Float64)和Decimal布尔:
Boolean字符串:
String和FixedString日期:使用
Date和Date32天,DateTime时间和DateTime64JSON:
JSON将JSON文档存储在单列中UUID:存储
UUID值的性能选项低基数类型:当您有少数唯一值时,请使用
Enum,或者当您拥有多达 10,000 个列的唯一值时,使用LowCardinality数组:任何列都可以定义为
Array地图:使用
Map存储键/值对聚合函数类型:使用
SimpleAggregateFunction和AggregateFunction存储聚合函数结果的中间状态嵌套数据结构:
Nested数据结构就像单元格内的表元组:元素
Tuple,每个元组都有单独的类型。Nullable:当值“缺失”时,
Nullable允许您将值存储为 NULL(而不是列设置其数据类型的默认值)IP地址:使用
IPv4和IPv6高效存储 IP 地址地理类型:用于地理数据,包括
Point、Ring、Polygon和MultiPolygon特殊数据类型:包括
Expression、Set、Nothing和Interval
数据库对象
ClickHouse 支持的数据库对象有:数据库、表、索引、视图、字典、函数、用户、角色、主键
函数为实例级别,与数据库无关
主键只是排序的一种手段,不保证唯一性
不支持外键、触发器、序列、规则、存储过程、自定义类型等
数据库
语法:
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster] [ENGINE = engine(...)]如果 db_name 数据库已经存在,则 ClickHouse 不会创建新数据库并且:
如果指定了子句,则不会引发异常。
如果未指定子句,则抛出异常。
示例:
create database clear engine = Atomic数据库引擎参考:官方文档
查询数据库信息:
在 ClickHouse 中,您可以使用 system 数据库中的表来查询数据库信息。例如,您可以使用 system.databases 表来获取数据库的名称和引擎类型。如下:
SELECT name, engine FROM system.databases WHERE name = 'db_uuid';┌─name────┬─engine─┐
│ db_uuid │ Atomic │
└─────────┴────────┘角色
语法:
CREATE ROLE [IF NOT EXISTS | OR REPLACE] name1 [ON CLUSTER cluster_name1] [, name2 [ON CLUSTER cluster_name2] ...]
[IN access_storage_type]
[SETTINGS variable [= value] [MIN [=] min_value] [MAX [=] max_value] [CONST|READONLY|WRITABLE|CHANGEABLE_IN_READONLY] | PROFILE 'profile_name'] [,...]一个用户可以被分配多个角色。用户可以通过 SET ROLE 语句以任意组合应用其分配的角色。特权的最终范围是所有应用角色的所有特权的组合集。如果用户拥有直接授予其用户帐户的特权,它们也会与角色授予的特权相结合。
用户可以拥有在用户登录时应用的默认角色。要设置默认角色,请使用 SET DEFAULT ROLE 语句或 ALTER USER 语句。
要撤销角色,请使用 REVOKE 语句。
要删除角色,请使用 DROP ROLE 语句。删除的角色将自动从分配给它的所有用户和角色中撤销。
示例:
CREATE ROLE accountant;
GRANT SELECT ON db.* TO accountant;用户
语法:
CREATE USER [IF NOT EXISTS | OR REPLACE] name1 [ON CLUSTER cluster_name1]
[, name2 [ON CLUSTER cluster_name2] ...]
[NOT IDENTIFIED | IDENTIFIED {[WITH {no_password | plaintext_password | sha256_password | sha256_hash | double_sha1_password | double_sha1_hash}] BY {'password' | 'hash'}} | {WITH ldap SERVER 'server_name'} | {WITH kerberos [REALM 'realm']} | {WITH ssl_certificate CN 'common_name' | SAN 'TYPE:subject_alt_name'} | {WITH ssh_key BY KEY 'public_key' TYPE 'ssh-rsa|...'} | {WITH http SERVER 'server_name' [SCHEME 'Basic']}]
[HOST {LOCAL | NAME 'name' | REGEXP 'name_regexp' | IP 'address' | LIKE 'pattern'} [,...] | ANY | NONE]
[VALID UNTIL datetime]
[IN access_storage_type]
[DEFAULT ROLE role [,...]]
[DEFAULT DATABASE database | NONE]
[GRANTEES {user | role | ANY | NONE} [,...] [EXCEPT {user | role} [,...]]]
[SETTINGS variable [= value] [MIN [=] min_value] [MAX [=] max_value] [READONLY | WRITABLE] | PROFILE 'profile_name'] [,...]设置用户认证方式:
IDENTIFIED WITH no_passwordIDENTIFIED WITH plaintext_password BY 'qwerty'IDENTIFIED WITH sha256_password BY 'qwerty'或IDENTIFIED BY 'password'IDENTIFIED WITH sha256_hash BY 'hash'或IDENTIFIED WITH sha256_hash BY 'hash' SALT 'salt'IDENTIFIED WITH double_sha1_password BY 'qwerty'IDENTIFIED WITH double_sha1_hash BY 'hash'IDENTIFIED WITH bcrypt_password BY 'qwerty'IDENTIFIED WITH bcrypt_hash BY 'hash'IDENTIFIED WITH ldap SERVER 'server_name'IDENTIFIED WITH kerberos或IDENTIFIED WITH kerberos REALM 'realm'IDENTIFIED WITH ssl_certificate CN 'mysite.com:user'IDENTIFIED WITH ssh_key BY KEY 'public_key' TYPE 'ssh-rsa', KEY 'another_public_key' TYPE 'ssh-ed25519'IDENTIFIED WITH http SERVER 'http_server'或IDENTIFIED WITH http SERVER 'http_server' SCHEME 'basic'IDENTIFIED BY 'qwerty'
密码复杂度要求可以在 config.xml 中编辑。以下是要求密码长度至少为 12 个字符并包含1个数字的示例配置。每个密码复杂性规则都需要一个和则表达符来匹配密码和规则的描述。
<clickhouse>
<password_complexity>
<rule>
<pattern>.{12}</pattern>
<message>be at least 12 characters long</message>
</rule>
<rule>
<pattern>\p{N}</pattern>
<message>contain at least 1 numeric character</message>
</rule>
</password_complexity>
</clickhouse>在 ClickHouse Cloud 中,默认情况下,密码必须满足以下复杂性要求:
长度至少为12个字符
包含至少1个数字字符
包含至少1个大写字符
包含至少1个小写字符
包含至少1个特殊字符
示例:
CREATE USER name2 IDENTIFIED WITH plaintext_password BY 'my_password'表
显式创建
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|EPHEMERAL|ALIAS expr1] [COMMENT 'comment for column'] [compression_codec] [TTL expr1], name2 [type2] [DEFAULT|MATERIALIZED|EPHEMERAL|ALIAS expr2] [COMMENT 'comment for column'] [compression_codec] [TTL expr2], ... ) ENGINE = engine COMMENT 'comment for table'在 db 数据库中创建一个名为
table_name的表,如果没有设置 db,则创建名为table_name的表,并在括号和engine引擎中指定结构。该表的结构是列描述、次要索引和约束的列表。如果主键由引擎支持,它将被指示为表引擎的参数。列描述是最简单情况下的 name type。示例:RegionID UInt32。
也可以为默认值定义表达式(见下文)。
如有必要,可以指定主键,使用一个或多个键表达式。
可以为列和表添加注释。
在 ClickHouse 中,
DEFAULT,MATERIALIZED,ALIAS和EPHEMERAL是用于在创建表时定义列行为的修饰符。DEFAULT:这个修饰符允许设置存储在数据库中的默认值。如果在插入数据时没有为该列提供值,那么将使用默认值。默认列可以在INSERT时选择性地提供。参考链接MATERIALIZED:这个修饰符存储值,但不允许在插入数据时传递值。这些列的值必须始终从其他列计算出来。此外,SELECT *将跳过MATERIALIZED列,它们必须特别请求。这允许将表转储重新加载回具有相同定义的表。参考链接ALIAS:这个修饰符在查询时计算值,但不将它们存储在数据库中。参考链接EPHEMERAL:这种类型的列不存储在表中,也不能从中选择。这些列的唯一目的是从它们构建其他列的默认值表达式。插入没有明确指定列的数据将跳过此类型的列。这是为了保持SELECT *的结果始终可以使用INSERT插回表的不变性。参考链接
复制其他表的结构
CREATE TABLE [IF NOT EXISTS] [db.]table_name AS [db2.]name2 [ENGINE = engine]创建一个结构与另一个表相同的表。您可以为表指定不同的引擎。如果未指定引擎,将使用与
db2.name2表相同的引擎。
使用表函数
CREATE TABLE [IF NOT EXISTS] [db.]table_name AS table_function()创建一个与指定表函数结果相同的表。创建的表也将以与指定的相应表函数相同的方式工作。
as selectCREATE TABLE [IF NOT EXISTS] [db.]table_name[(name1 [type1], name2 [type2], ...)] ENGINE = engine AS SELECT ...
视图
普通视图
语法:
CREATE [OR REPLACE] VIEW [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster_name] AS SELECT ...普通视图不存储任何数据。 他们只是在每次访问时从另一个表执行读取。换句话说,普通视图只不过是一个保存的查询。 从视图中读取时,此保存的查询用作 FROM 子句中的子查询.
示例:
create or replace view if not exists view1 as select * from user_101物化视图
语法:
CREATE MATERIALIZED VIEW [IF NOT EXISTS] [db.]table_name [ON CLUSTER] [TO[db.]name] [ENGINE = engine] [POPULATE] AS SELECT ...物化视图存储由相应的 SELECT 管理.
创建不带 TO [db].[table] 的物化视图时,必须指定 ENGINE – 用于存储数据的表引擎。
使用 TO [db].[table] 创建物化视图时,不得使用 POPULATE。
一个物化视图的实现是这样的:当向 SELECT 中指定的表插入数据时,插入数据的一部分被这个 SELECT 查询转换,结果插入到视图中。
⚠️ "重要" ClickHouse 中的物化视图更像是插入触发器。 如果视图查询中有一些聚合,则它仅应用于一批新插入的数据。 对源表现有数据的任何更改(如更新、删除、删除分区等)都不会更改物化视图。
如果指定POPULATE,则在创建视图时将现有表数据插入到视图中,就像创建一个 CREATE TABLE ... AS SELECT ... 一样。 否则,查询仅包含创建视图后插入表中的数据。 我们不建议使用POPULATE,因为在创建视图期间插入表中的数据不会插入其中。
SELECT 查询可以包含 DISTINCT、GROUP BY、ORDER BY、LIMIT...请注意,相应的转换是在每个插入数据块上独立执行的。 例如,如果设置了 GROUP BY,则在插入期间聚合数据,但仅在插入数据的单个数据包内。 数据不会被进一步聚合。 例外情况是使用独立执行数据聚合的 ENGINE,例如 SummingMergeTree。
在物化视图上执行 ALTER 查询有局限性,因此可能不方便。 如果物化视图使用构造 TO [db.]name,你可以 DETACH 视图,为目标表运行 ALTER,然后 ATTACH 先前分离的(DETACH)视图。
请注意,物化视图受optimize_on_insert设置的影响。 在插入视图之前合并数据。
视图看起来与普通表相同。 例如,它们列在 SHOW TABLES 查询的结果中。
删除视图,使用 DROP VIEW. DROP TABLE 也适用于视图。
示例:
create materialized view mv1 engine = MergeTree order by id as select * from user_101;函数
⚠️ ClickHouse 数据库函数不是数据库特定的,而是全局的,21.10 版本开始支持创建函数
从 lambda 表达式创建用户定义函数(UDF)。表达式必须由函数参数、常量、运算符或其他函数调用组成。
语法
CREATE FUNCTION name [ON CLUSTER cluster] AS (parameter0, ...) -> expression一个函数可以有任意数量的参数。
有一些限制:
函数的名称在用户定义和系统函数中必须是唯一的。
不允许递归函数。
函数使用的所有变量必须在其参数列表中指定。
示例:
create function f1 as (a, b, c) -> a + b * c;
select f1(1, 2, 3);用户表中可以使用自定义函数做默认值等,如下:
create table test (
id int,
num int default f1(1, 2, 3)
)查询所有自定义函数
select * from system.functions where origin = 'SQLUserDefined'通过以下sql来判断是否支持自定义函数
select count(0) from system.columns where database = 'system' and table = 'functions' and name = 'origin';如果函数之间存在依赖关系,如下:
create function f1 as (a) -> 1;
create function f2 as (a) -> f1(1);如果 f2 先于 f1 创建也是可以创建成功的,只是使用f2的时候如果还没有创建f1会报错
对于不同实例之间的脱敏,无法查询出某张表/视图使用了哪些函数,直接将所有自定义函数迁移
字典
在 ClickHouse 中,字典是一种映射(键-值对或键-属性对)的数据结构,它对于各种类型的参考列表非常方便。字典在查询中的使用通常比使用参考表的 JOIN 更有效率。
语法:
CREATE [OR REPLACE] DICTIONARY [IF NOT EXISTS] [db.]dictionary_name [ON CLUSTER cluster]
(
key1 type1 [DEFAULT|EXPRESSION expr1] [IS_OBJECT_ID],
key2 type2 [DEFAULT|EXPRESSION expr2],
attr1 type2 [DEFAULT|EXPRESSION expr3] [HIERARCHICAL|INJECTIVE],
attr2 type2 [DEFAULT|EXPRESSION expr4] [HIERARCHICAL|INJECTIVE]
)
PRIMARY KEY key1, key2
SOURCE(SOURCE_NAME([param1 value1 ... paramN valueN]))
LAYOUT(LAYOUT_NAME([param_name param_value]))
LIFETIME({MIN min_val MAX max_val | max_val})
SETTINGS(setting_name = setting_value, setting_name = setting_value, ...)
COMMENT 'Comment'字典结构由属性组成。字典属性的指定与表列类似。唯一需要的属性属性是其类型,所有其他属性可能具有默认值。
ON CLUSTER 子句允许在集群上创建字典,请参阅分布式DDL。
根据字典布局,可以将一个或多个属性指定为字典键。
示例:
CREATE DICTIONARY id_value_dictionary
(
id UInt64,
value String
)
PRIMARY KEY id
SOURCE(CLICKHOUSE(TABLE 'source_table'))
LAYOUT(FLAT())
LIFETIME(MIN 0 MAX 1000)查询某个数据库下所有的字典信息:
SELECT * FROM system.dictionaries where database = '数据库' and name = '字典名';查询某个字典的 ddl:
show create dictionary 字典名;索引
⚠️20.5版本不支持
创建数据跳过索引: 数据跳过索引可以在 *MergeTree 系列的表上指定。这些索引在由 granularity_value 粒度组成的块上聚合有关指定表达式的一些信息,然后在 SELECT 查询中使用这些聚合来通过跳过无法满足 where 查询的大数据块来减少从磁盘读取的数据量。以下是创建数据跳过索引的示例:
CREATE TABLE table_name
(
u64 UInt64,
i32 Int32,
s String,
...
INDEX idx1 u64 TYPE bloom_filter GRANULARITY 3,
INDEX idx2 u64 * i32 TYPE minmax GRANULARITY 3,
INDEX idx3 u64 * length(s) TYPE set(1000) GRANULARITY 4
) ENGINE = MergeTree()
...请注意,索引在 ClickHouse 中的使用与传统的关系数据库管理系统有所不同。在 ClickHouse 中,索引主要用于提高查询性能,而不是保证数据的唯一性或完整性。
参考:数据跳过索引
查询数据跳过索引信息:
SELECT * FROM system.data_skipping_indices WHERE database = '数据库名' and table = 'my_table'分区
在 ClickHouse 中,MergeTree 家族的表引擎支持创建分区。这包括 MergeTree,ReplicatedMergeTree,SummingMergeTree,AggregatingMergeTree,ReplacingMergeTree 等等。
语法:
CREATE TABLE visits
(
VisitDate Date,
Hour UInt8,
ClientID UUID
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(VisitDate)
ORDER BY Hour;在这个例子中,我们使用 toYYYYMM(VisitDate) 表达式按月创建分区。
请注意,大多数情况下,您不需要分区键,如果需要分区,通常不需要比按月更精细的分区键。分区并不会加速查询(与 ORDER BY 表达式相反)。您不应该使用过于精细的分区。不要按客户标识符或名称分区数据(相反,应该将客户标识符或名称作为 ORDER BY 表达式中的第一列)。
获取分区信息:
SELECT * FROM system.parts WHERE database = '数据库名' and table = '表名'分页
LIMIT m 允许从结果中选择前 m 行。
LIMIT n, m 允许在跳过前 n 行后从结果中选择 m 行。LIMIT m OFFSET n 语法是等价的。
n m 必须是非负整数。
如果没有明确排序结果的 ORDER BY 子句,则结果的行选择可能是任意的和非确定性的。
静态脱敏在拆分线程时,通过一下方式查询表的排序规则:
select sorting_key from system.tables where database = '数据库' and name = '表名'对于有主键的表
ClickHouse 主键不保证唯一性,不能为空
如果主键是有一个字段是数值主键,可以按照
between..and进行分页-- 查询某张表的主键及主键类型 select name, type from system.columns where database = 'default' and table = 'test4' and is_in_primary_key = 1;
对于有分区键的表
无法通过查询指定分区数据,按照主键、或者普通表分页
对于其他表
如果表存在排序字段,按照表排序字段进行排序分页
-- 查询表的排序表达式 select sorting_key from system_tables where database = '' and name = ''; -- 按照排序表达式进行排序 select * from 表 order by sorting_key limit 0 , 1000;
权限
授予 ClickHouse 用户帐户或角色的特权。
将角色分配给用户帐户或其他角色。
要撤销特权,请使用 REVOKE 语句。您还可以通过 SHOW GRANTS 语句列出授予的特权。
语法:
GRANT [ON CLUSTER cluster_name] privilege[(column_name [,...])] [,...] ON {db.table|db.*|*.*|table|*} TO {user | role | CURRENT_USER} [,...] [WITH GRANT OPTION] [WITH REPLACE OPTION]privilege— 特权类型。
role—ClickHouse用户角色。
user— ClickHouse用户帐户。
WITH GRANT OPTION 子句授予 user 或 role 执行 GRANT 查询的权限。用户可以授予他们拥有的相同范围的特权,并且更少。WITH REPLACE OPTION 子句将旧权限替换为 user or role 的新权限,如果未指定,则附加特权。
权限层次结构:
ALTER UPDATE
ALTER DELETE
ALTER COLUMN
ALTER ADD COLUMN
ALTER DROP COLUMN
ALTER MODIFY COLUMN
ALTER COMMENT COLUMN
ALTER CLEAR COLUMN
ALTER RENAME COLUMN
ALTER INDEX
ALTER ORDER BY
ALTER ADD INDEX
ALTER DROP INDEX
ALTER MATERIALIZE INDEX
ALTER CLEAR INDEX
ALTER CONSTRAINT
ALTER ADD CONSTRAINT
ALTER DROP CONSTRAINT
ALTER TTL
ALTER MATERIALIZE TTL
ALTER SETTINGS
ALTER MOVE PARTITION
ALTER FETCH PARTITION
ALTER FREEZE PARTITION
ALTER VIEW
ALTER VIEW REFRESH
ALTER VIEW MODIFY QUERY
CREATE DATABASE
CREATE TABLE
CREATE VIEW
CREATE DICTIONARY
CREATE TEMPORARY TABLE
DROP DATABASE
DROP TABLE
DROP VIEW
DROP DICTIONARY
SHOW DATABASES
SHOW TABLES
SHOW COLUMNS
SHOW DICTIONARIES
CREATE USER
ALTER USER
DROP USER
CREATE ROLE
ALTER ROLE
DROP ROLE
CREATE ROW POLICY
ALTER ROW POLICY
DROP ROW POLICY
CREATE QUOTA
ALTER QUOTA
DROP QUOTA
CREATE SETTINGS PROFILE
ALTER SETTINGS PROFILE
DROP SETTINGS PROFILE
SHOW ACCESS
SHOW_USERS
SHOW_ROLES
SHOW_ROW_POLICIES
SHOW_QUOTAS
SHOW_SETTINGS_PROFILES
ROLE ADMIN
SYSTEM SHUTDOWN
SYSTEM DROP CACHE
SYSTEM DROP DNS CACHE
SYSTEM DROP MARK CACHE
SYSTEM DROP UNCOMPRESSED CACHE
SYSTEM RELOAD
SYSTEM RELOAD CONFIG
SYSTEM RELOAD DICTIONARY
SYSTEM RELOAD EMBEDDED DICTIONARIES
SYSTEM MERGES
SYSTEM TTL MERGES
SYSTEM FETCHES
SYSTEM MOVES
SYSTEM SENDS
SYSTEM DISTRIBUTED SENDS
SYSTEM REPLICATED SENDS
SYSTEM REPLICATION QUEUES
SYSTEM SYNC REPLICA
SYSTEM RESTART REPLICA
SYSTEM FLUSH
SYSTEM FLUSH DISTRIBUTED
SYSTEM FLUSH LOGS
addressToLine
addressToSymbol
demangle
FILE
URL
REMOTE
YSQL
ODBC
JDBC
HDFS
S3
级别(由低到高,各个权限的级别参考官方文档):
COLUMN - 可以授权到列,表,库或者全局
TABLE - 可以授权到表,库,或全局
VIEW - 可以授权到视图,库,或全局
DICTIONARY - 可以授权到字典,库,或全局
DATABASE - 可以授权到数据库或全局
GLABLE - 可以授权到全局
GROUP - 不同级别的权限分组。当授予 GROUP 级别的权限时, 根据所用的语法,只有对应分组中的权限才会被分配。
大小写
数据库对象严格区分大小写,不需要使用符号区分,如下:
create table test (
col String,
Col String,
COL String
) engine = MergeTree order by id;
create table Test (
col String,
Col String,
COL String
) engine = MergeTree order by id;
create table TEST (
col String,
Col String,
COL String
) engine = MergeTree order by id;
select * from test;
select * from Test;
select * from TEST;数据库对象可以包含特殊字符,使用时需要使用`或"包裹,如下:
create table "123" (
id int,
name String
) engine = MergeTree order by id;性能
查询性能
JDBC
引入依赖:
<dependency> <groupId>com.clickhouse</groupId> <artifactId>clickhouse-jdbc</artifactId> <version>0.6.0</version> <!-- use uber jar with all dependencies included, change classifier to http for smaller jar --> <classifier>all</classifier> </dependency>支持 jdbc 流式读取
String url = "jdbc:ch://10.21.20.162:8123/clear"; Properties properties = new Properties(); ClickHouseDataSource dataSource = new ClickHouseDataSource(url, properties); try (Connection conn = dataSource.getConnection("default", "123456"); Statement statement = conn.createStatement()) { ResultSet resultSet = statement.executeQuery("select * from user_101"); while (resultSet.next()) { } }在实际测试时不需要进行特殊设置,读取均为流式读取
Java Client
引入依赖:
<dependency> <groupId>com.clickhouse</groupId> <!-- or clickhouse-grpc-client if you prefer gRPC --> <artifactId>clickhouse-http-client</artifactId> <version>0.6.0</version> </dependency> <!-- 从版本0.5.0开始,驱动程序使用一个新的客户端http库,该库需要作为依赖项添加。 --> <dependency> <groupId>org.apache.httpcomponents.client5</groupId> <artifactId>httpclient5</artifactId> <version>5.2.3</version> </dependency>流式读取:
long l = System.currentTimeMillis(); ClickHouseNode server = ClickHouseNode.builder() .host(System.getProperty("chHost", "10.21.20.162")) .port(ClickHouseProtocol.HTTP, Integer.getInteger("chPort", 8123)) .database("clear") .credentials(ClickHouseCredentials.fromUserAndPassword( System.getProperty("chUser", "default"), System.getProperty("chPassword", "123456"))) .build(); try (ClickHouseClient client = ClickHouseClient.newInstance(ClickHouseProtocol.HTTP); ClickHouseResponse response = client.read(server) .format(ClickHouseFormat.RowBinaryWithNamesAndTypes) .query("select * from test") .executeAndWait()) { for (ClickHouseRecord r : response.records()) { int num = r.getValue(0).asInteger(); // System.err.println(num); } } System.err.println(System.currentTimeMillis() - l);
性能对比
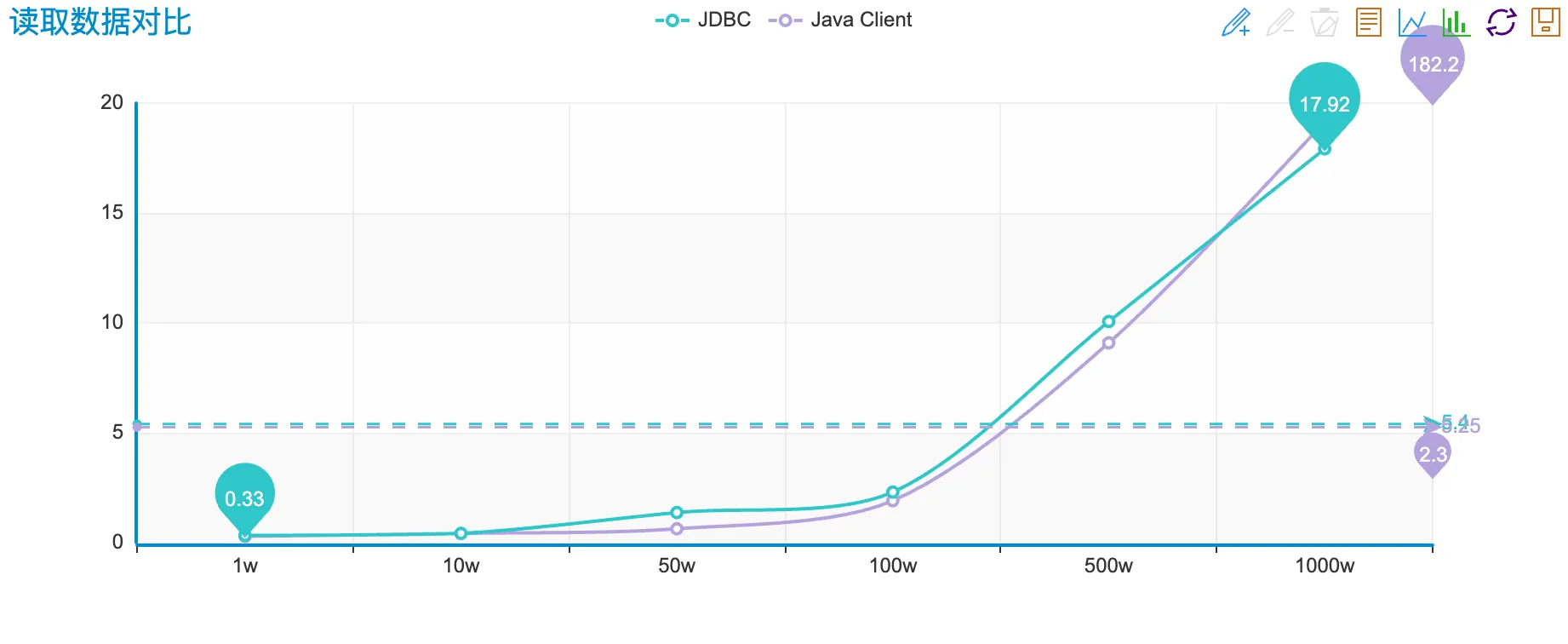
插入性能
表DDL
create table test(
id int,
name String
) engine = LogJDBC
public static void test6(int size) throws Exception { String url = "jdbc:clickhouse://10.21.171.18:30123/default"; Properties properties = new Properties(); properties.setProperty("socket_keepalive", "true"); properties.setProperty("buffer_size", "8192"); properties.setProperty("socket_rcvbuf", "804800"); properties.setProperty("socket_sndbuf", "804800"); ClickHouseDataSource dataSource = new ClickHouseDataSource(url, properties); try (Connection conn = dataSource.getConnection("admin", "890iop*()IOP")) { long l = System.currentTimeMillis(); // try (PreparedStatement ps = conn.prepareStatement("insert into test select col1, col2 from input('col1 int, col2 String')")) { try (PreparedStatement ps = conn.prepareStatement("insert into test values(?, ?)")) { for (int i = 0; i < size; i++) { if (i % 10000 == 0) { ps.executeBatch(); ps.clearBatch(); } ps.setObject(1, i); ps.setObject(2, "张三"); ps.addBatch(); } ps.executeBatch(); } System.err.println("写入:" + size + ",用时:" + (System.currentTimeMillis() - l)); } }Java Client
public static void test7() throws Exception { long l = System.currentTimeMillis(); ClickHouseNode server = ClickHouseNode.builder() .host(System.getProperty("chHost", "10.21.171.18")) .port(ClickHouseProtocol.HTTP, Integer.getInteger("chPort", 30123)) .database("default") .credentials(ClickHouseCredentials.fromUserAndPassword( System.getProperty("chUser", "admin"), System.getProperty("chPassword", "890iop*()IOP"))) .build(); ClickHouseFile file = ClickHouseFile.of("/Users/clear/Downloads/test.csv", ClickHouseCompression.NONE, ClickHouseFormat.CSV); try (ClickHouseClient client = ClickHouseClient.newInstance(ClickHouseProtocol.HTTP); ClickHouseResponse response = client.write(server) .option(ClickHouseClientOption.SOCKET_TIMEOUT, 1200000) .option(ClickHouseClientOption.CONNECTION_TIMEOUT, 1200000) .option(ClickHouseClientOption.BUFFER_SIZE, 8192) .option(ClickHouseClientOption.SOCKET_RCVBUF, 804800) .option(ClickHouseClientOption.SOCKET_SNDBUF, 804800) .set("format_csv_delimiter", ",") .table("test") .data(file) .executeAndWait()) { ClickHouseResponseSummary summary = response.getSummary(); long writtenRows = summary.getWrittenRows(); System.err.println("写入:" + writtenRows + ",用时:" + (System.currentTimeMillis() - l)); } }性能对比
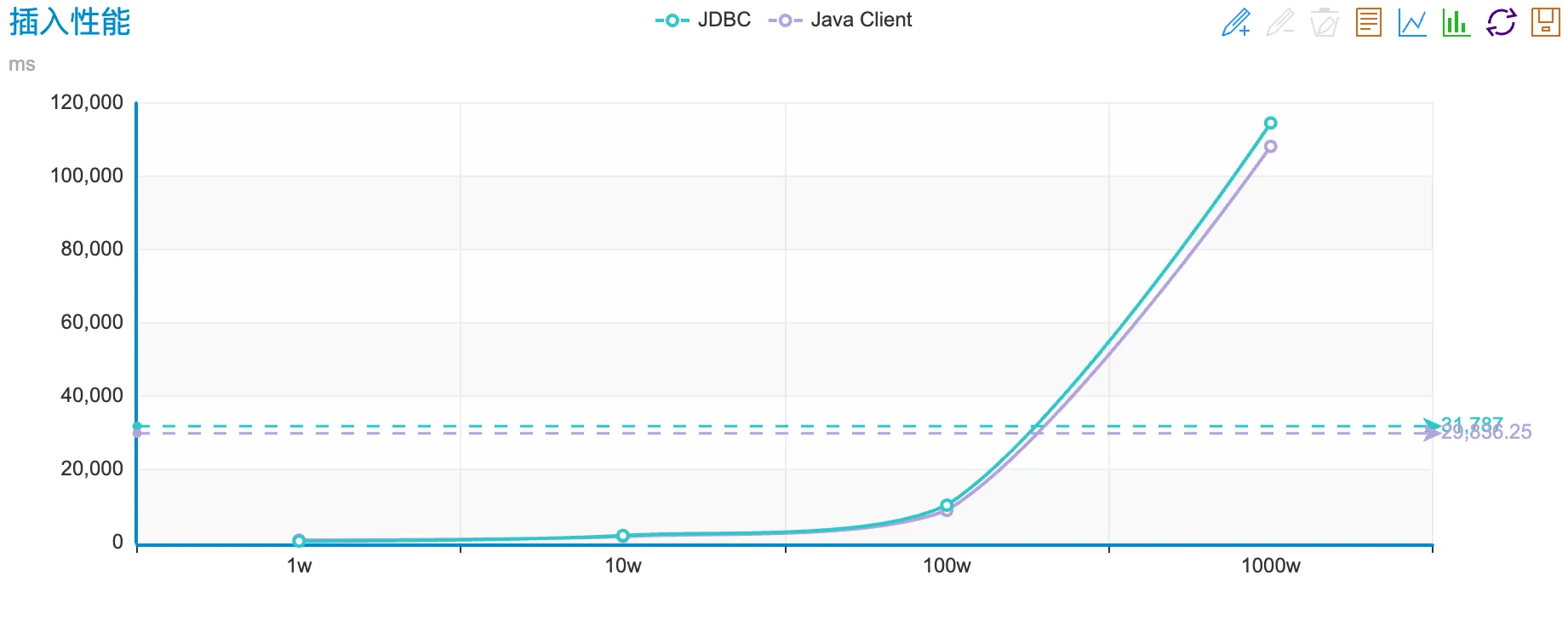
引擎
数据库引擎
MySQL
MySQL 引擎用于将远程的 MySQL 服务器中的表映射到 ClickHouse 中,并允许您对表进行 INSERT 和 SELECT 查询,以方便您在 ClickHouse 与 MySQL 之间进行数据交换
MySQL 数据库引擎会将对其的查询转换为 MySQL 语法并发送到 MySQL 服务器中,因此您可以执行诸如 SHOW TABLES 或 SHOW CREATE TABLE 之类的操作。
但您无法对它执行以下操作:
RENAMECREATE TABLEALTER
语法:
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster]
ENGINE = MySQL('host:port', ['database' | database], 'user', 'password')目标数据源不应为此引擎
Lazy
在最后一次访问之后,只在 RAM 中保存 expiration_time_in_seconds 秒。只能用于 *Log 表。
它是为存储许多小的 *Log 表而优化的,对于这些表,访问之间有很长的时间间隔。
语法:
CREATE DATABASE testlazy ENGINE = Lazy(expiration_time_in_seconds);Atomic
它支持非阻塞的 DROP TABLE 和 RENAME TABLE 查询和原子的 EXCHANGE TABLES t1 AND t2 查询。默认情况下使用 Atomic 数据库引擎。
语法:
CREATE DATABASE test[ ENGINE = Atomic];SQLite
允许连接到 SQLite 数据库,并支持 ClickHouse 和 SQLite 交换数据, 执行 INSERT 和 SELECT 查询。
语法:
CREATE DATABASE sqlite_database
ENGINE = SQLite('db_path')PostgreSQL
允许连接到远程 PostgreSQL 服务。支持读写操作(SELECT 和 INSERT 查询),以在 ClickHouse 和 PostgreSQL 之间交换数据。
在 SHOW TABLES 和 DESCRIBE TABLE 查询的帮助下,从远程 PostgreSQL 实时访问表列表和表结构。
支持表结构修改(ALTER TABLE ... ADD|DROP COLUMN)。如果 use_table_cache 参数(参见下面的引擎参数)设置为 1,则会缓存表结构,不会检查是否被修改,但可以用 DETACH 和 ATTACH 查询进行更新。
语法:
CREATE DATABASE test_database
ENGINE = PostgreSQL('host:port', 'database', 'user', 'password'[, `use_table_cache`]);表引擎
参考:表引擎
对于远程表,以 MySQL 引擎为例:
MySQL 引擎可以对存储在远程 MySQL 服务器上的数据执行 SELECT 查询。
语法:
create table test (
id int,
name String
) engine = MySQL('host:port', 'database', 'table', 'user', 'password'[, replace_query, 'on_duplicate_clause']);脱敏时创建表,应修改数据库引擎,使其成为 ClickHouse 的普通表,如下:
create table test (
id int,
name String
) engine = MergeTree order by tuple();数据不需要进行排序时使用 order by tuple()
其他
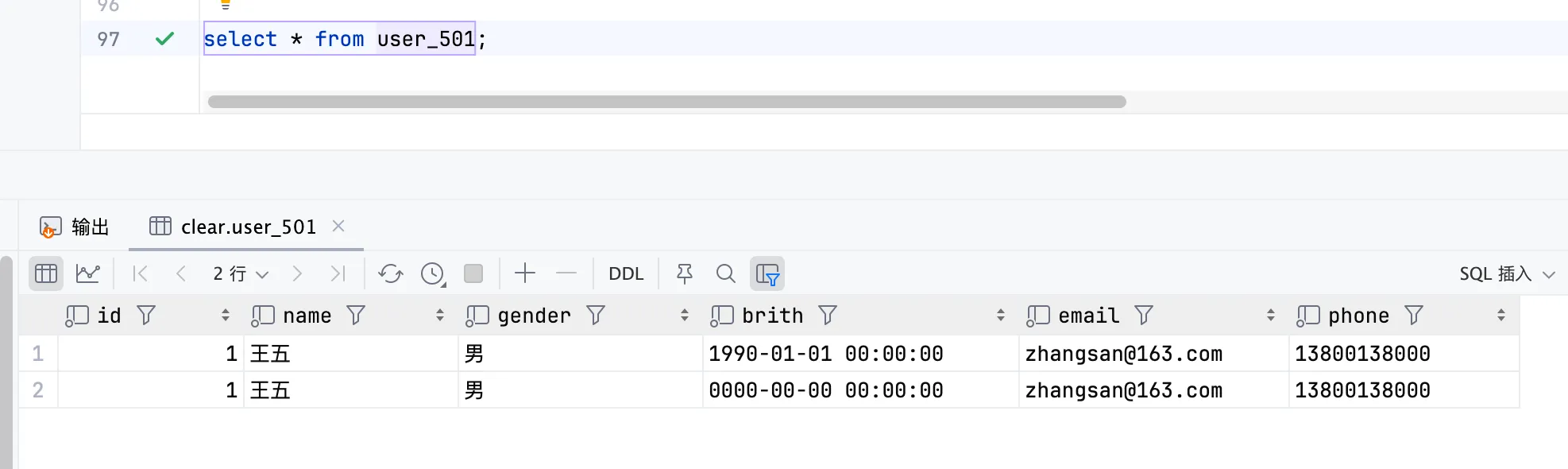
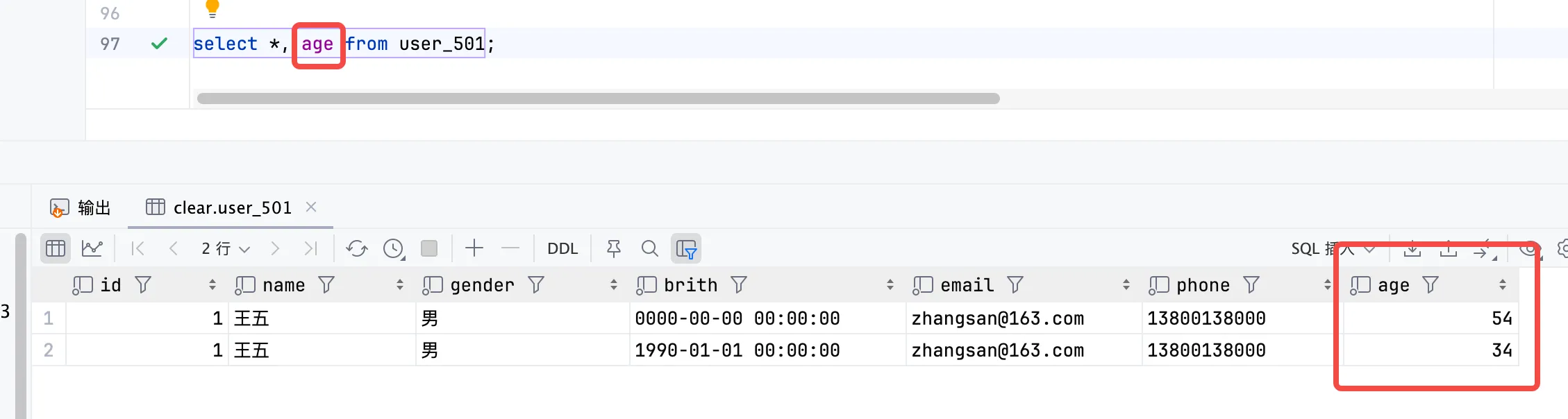
虚拟列
使用 MATERIALIZED、ALIAS 可以为列设置计算值,即计算列。不能插入值,无法使用 select * 查处该列,需要 select column 才能查询到,如下:
create table user_501
(
id Int64,
name String default '张三',
gender String,
brith DateTime,
age Int32 alias dateDiff('year', brith, now()),
email FixedString(20),
phone FixedString(20)
) engine = MergeTree ORDER BY id;